

Backup and Restore Azure Cognitive Search Indexes with Powershell
For me, the story started with the need for prepopulating some Azure Cognitive Search indexes. I had a beautiful index loaded up from various CSV files and enhanced with Cognitive Skills. I was working on a lab environment for students who would consume the index but would not necessarily build it. Additionally, building the index from scratch for every lab environment instance does not make sense if the resulting data is the same. It would be just a waste of computing resources on the preparation and enrichment front.
Unfortunately, as of January 2020, Azure Cognitive Search does not have a Backup/Restore or Export functionality. It has Import, but that relies on the indexers, which does not help as it runs the full process of ingesting raw input data and processing to feed the index.
Another area where having a backup/restore functionality can help is when you need to move between pricing tiers. Unfortunately, Azure Cognitive Search does not allow you to move between pricing tiers. As a result, you have to create a new service account and transfer your data and index manually.
The Backup
The first step is to get the index schema out. To be a little more friendly, I decided to get a list of indexes first and let the user select the one that needs the export.
#Getting a list of indexes for user selection
$result = Invoke-RestMethod -Uri $uri -Method GET -Headers $headers `
-ContentType "application/json" | Select-Object -ExpandProperty value
$indexOptions = [System.Collections.ArrayList]::new()
for($indexIdx=0; $indexIdx -lt $result.length; $indexIdx++)
{
$opt = New-Object System.Management.Automation.Host.ChoiceDescription `
"$($result[$indexIdx].Name)", `
"Selects the $($result[$indexIdx].Name) index."
$indexOptions.Add($opt)
}
$selectedIndexIdx = $host.ui.PromptForChoice('Enter the desired Index', `
'Copy and paste the name of the index to make your choice.', `
$indexOptions.ToArray(),0)
$selectedIndexName = $result[$selectedIndexIdx]
Now that we know what index to backup, getting the schema for the index is very straightforward.
$uri = $serviceUri `
+ "/indexes/$($selectedIndexName.Name)?api-version=2019-05-06"
$result = Invoke-RestMethod -Uri $uri -Method GET -Headers $headers `
-ContentType "application/json" |
ConvertTo-Json -Depth 9 |
Set-Content "$($selectedIndexName.Name).schema"
The final step is to download the documents from the index. We have to use the Search API to access documents. There is no other way. The API has $skip and $top parameters that allows paging the result set. There are continuation tokens, but those are simply the search endpoint URL with an incremental skip and top values. One critical issue is the BM25 scoring that might shift data while our code iterates through pages. Another problem is if you have other applications interacting with the index that can trigger various data changes. Therefore, there isn’t a guaranteed way of making sure you have a proper full backup. You might want to check document counts at least once after you restore the data to a new index. It will give you some level of confidence.
While getting the document count I got into some weird encoding issues with Powershell’s Invoke-RestMethod or Invoke-WebRequest. After some timeboxed research, I decided to fall back to System.Net.WebRequest. It worked, so I moved on.
$uri = $serviceUri `
+ "/indexes/$($selectedIndexName.Name)/docs/`$count?api-version=2020-06-30"
$req = [System.Net.WebRequest]::Create($uri)
$req.ContentType = "application/json; charset=utf-8"
$req.Accept = "application/json"
$req.Headers["api-key"] = $targetAdminKey
$resp = $req.GetResponse()
$reader = new-object System.IO.StreamReader($resp.GetResponseStream())
$result = $reader.ReadToEnd()
$documentCount = [int]$result
To download documents faster, I decided to parallelize the code. With their introduction in Powershell 7, ForEach-Object -Parallel with a nice ThrottleLimit parameter and ability to Receive-Job -Wait, similar to WaitAll in C#, makes everything so comfortable.
$pageCount = [math]::ceiling($documentCount / 500)
$job = 1..$pageCount | ForEach-Object -Parallel {
$skip = ($_ - 1) * 500
$uri = $using:serviceUri + "/indexes/$($using:selectedIndexName.name)/docs?api-version=2020-06-30&search=*&`$skip=$($skip)&`$top=500&searchMode=all"
Invoke-RestMethod -Uri $uri -Method GET -Headers $using:headers -ContentType "application/json" |
ConvertTo-Json -Depth 9 |
Set-Content "$($using:selectedIndexName.Name)_$($_).json"
"Output: $uri"
} -ThrottleLimit 5 -AsJob
$job | Receive-Job -Wait
Once you run the script, you will end up with a schema file and a bunch of JSON files, each having 500 documents in them.
The Restore
The first step to restore the index is to put the index schema in.
$indexSchemaFile = Get-Content -Raw -Path $selectedIndexNameFile
$selectedIndexName = ($indexSchemaFile | ConvertFrom-Json).name
# Createing the Index
Write-Host "Creating Target Search Index."
$result = Invoke-RestMethod -Uri $uri -Method POST -Body $indexSchemaFile `
-Headers $headers -ContentType "application/json"
Once that is done, the rest is merely uploading the JSON documents as they are. The Add Document API in Azure Cognitive Search does accept multiple documents in one batch. That makes it very easy to upload the stored JSON files that we have straight to the API.
$uri = $serviceUri `
+ "/indexes/$($selectedIndexName)/docs/index?api-version=2019-05-06"
$files = Get-ChildItem "." -Filter *.json
foreach ($f in $files){
$content = Get-Content $f.FullName
Write-Host "Uploading documents from file" $f.Name
$result = Invoke-RestMethod -Uri $uri -Method POST -Body $content `
-Headers $headers -ContentType "application/json; charset=utf-8"
}
That’s it. You now have a copy of your index with the data. Let’s check the document count to see if the number of documents is the same in both indexes.
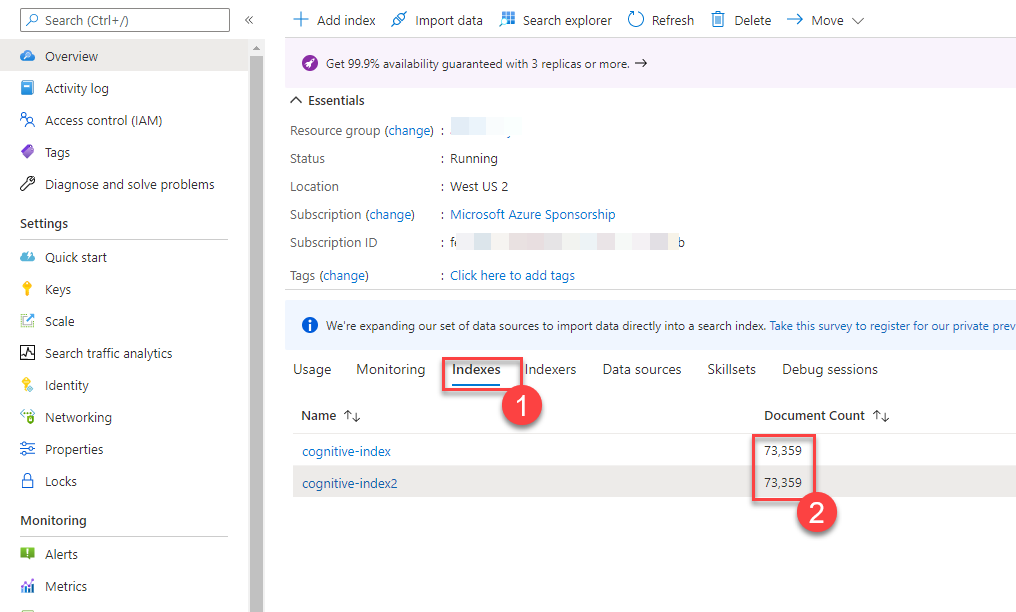
One final reminder, the $skip parameter we used to page through the documents only supports numbers up to 100.000. If you have a larger index, you will need to find some other paging strategy. For example, you might be able to use $orderby and $filter with a range query on a field across your documents to page through the index.
I hope this little snippet helps. Here is the GitHub repo that has the full-sized PS1 scripts. If you are looking for a C# version, you can find one here that goes pretty much through the same steps with the same limitations.
Resources
- Add, Update or Delete Documents (Azure Cognitive Search REST API)
- azure-search-index-backup-restore-powershell Github Repo
- Back up and restore an Azure Cognitive Search index
- Count Documents (Azure Cognitive Search REST API)
- Create Index (Azure Cognitive Search REST API)
- ForEach-Object
- Get Index (Azure Cognitive Search REST API)
- Import data wizard for Azure Cognitive Search
- List Indexes (Azure Cognitive Search REST API)
- Practical BM25 - Part 2: The BM25 Algorithm and its Variables
- Receive-Job
- Search Documents (Azure Cognitive Search REST API)
- Skillset concepts in Azure Cognitive Search

The first step starts with you
Get in touch!
The bigger the challenge, the more excited we get. Don’t be shy, throw it at us. We live to build solutions that work for you now and into the future. Get to know more about who we are, what we do, and the resources on our site. Drop a line and let’s connect.
